AI Foundation Models to Augment Scientific Data and the Research Lifecycle
by Rahul Ramachandran
This short blog describes our journey towards AI foundation models and how they can augment the science data and research lifecycle.
The Backstory
NASA’s science mission is to answer compelling and profound science questions about the universe. To help answer these questions, the agency has collected vast amounts of data, which have played a pivotal role in accelerating scientific discovery. A canonical example in Earth science comes from the early 1960s when NASA was launching experimental weather satellites for the National Weather Bureau. The TIROS series was extremely successful in providing a completely new perspective from space and continued for two decades. The figure below shows a beautiful black-and-white image containing an anomalous cloud line. This was attributed to smoke plumes from ships over the Atlantic. This observation led to research into aerosols, their impact on the environment, radiation budget, and of course, climate change. This is now a wide and active area of research and a great example of how NASA’s data changes the direction of science. It has done so in the past and will continue to do so in the future.

NASA has the world’s largest collection of Earth observation data. This vast collection is driven by our mission to understand our planet as a unified system. These observations cover all the major disciplines within Earth science — land, atmosphere, ocean, cryosphere, and human dimensions. Based on 2021 archive metrics, Earth science data volumes are now approximately 60 petabyte (Pb) and projected to grow to 250 Pb with the upcoming launch of two high data rate missions. For a sense of scale, 1 Pb is approximately the equivalent of 500 billion pages of printed text.
The archive served 1.7 million users worldwide, with about 2 billion files distributed to the hands of end users.
Making Science Happen
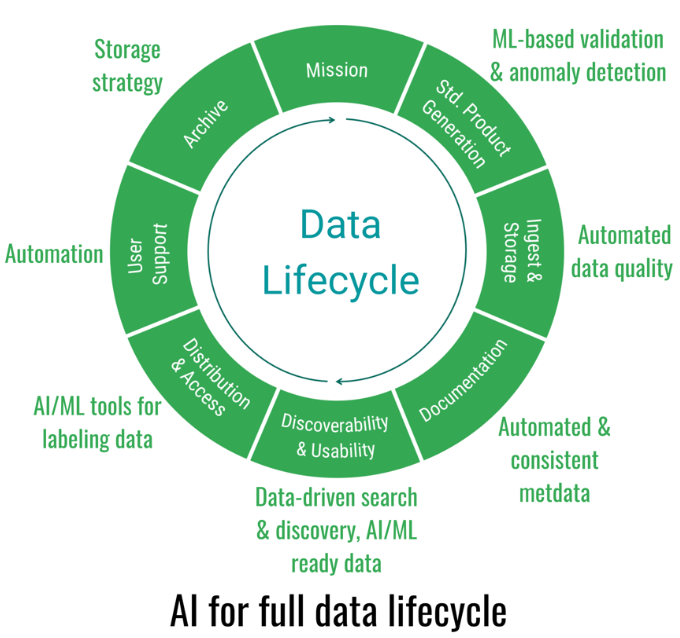
The data and the research lifecycle figure below encapsulates the building blocks that make science and applications happen. The data is in the center because it is the center of gravity; however circling these data is a complex, engineered data lifecycle process that enables the creation, management, distribution, and preservation of the data. The data lifecycle has many steps, and each step is iterative. Wrapped around the lifecycle process is a layer of tools and infrastructure. The data, data lifecycle, tools, and infrastructure are what enable research and application — the outer circle.
How can we continuously energize and streamline the research process and lower the barrier of entry to leverage our complete scientific datasets effectively? This is the charge of the IMPACT project.

Role of AI Foundation Models
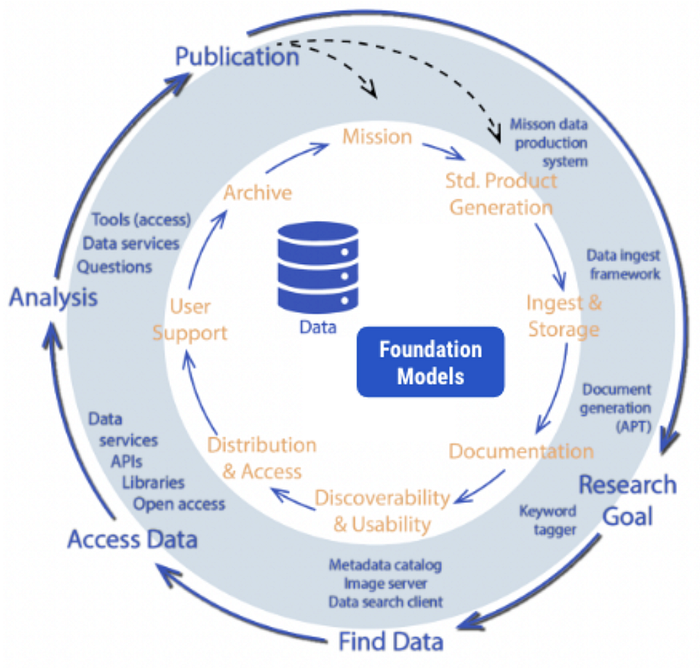
AI can play a critical role to improve and augment the discovery, access, and use of scientific data. To do so, AI has to be systematically infused into both our internal processes (the data lifecycle as shown in the figure below) and into the research process. Doing so in new and innovative ways will accelerate scientific discovery.
Our first foray into foundation models started by building an Earth science-specific language model. The first version, called BERT-E, was built by fine-tuning the existing BERT model. While the performance of the model can be substantially improved, even in its current state, the model is useful in downstream tasks.
At this time, we started our collaboration with the IBM Research team. These public-private collaborations using Space Act Agreements are part of our systematic strategy to engage the private industry to serve as “convergence accelerators” — to infuse innovation. The IBM team built an Earth science domain-specific model from scratch using a large corpus of over ~100 thousand Earth science journal papers. The value of building a domain-specific model can be seen in the sentence completion examples below. The results from the ES language model are precise as compared to vague answers from the generic model.

We plan to incorporate this new model into our existing operational processes. One application is to utilize this improved model in our science keyword tagging service. Using the Earth science-specific language model to build a keyword classifier will reduce inconsistencies and assist data stewards in objectively selecting optimal science keywords. Proper science keyword annotation of the data descriptions will, in turn, improve the search and discovery of the datasets. Another application is to support the Satellite Needs Working Group (SNWG) assessment process. Every two years, all civil federal agencies send their Earth observation needs to NASA. In the past two cycles, we have received close to 120 needs descriptions. These needs have to be binned into different NASA science thematic areas and then sent to the program scientists and their teams leading the assessment process for each specific theme. During the past two cycles, a single project principal was responsible for reading all the needs descriptions and assigning them to different themes. Using the language model has allowed us to develop a simple thematic classifier to substantially reduce the effort of the project principal and shorten the process of developing responses.
During our collaboration, the IBM Research team shared a paper on foundation models. Foundation models (FM) are AI models pretrained on comprehensive datasets using self supervised learning and can be used for many different downstream tasks. The datasets need to be sequential in nature, and that removes the need for having large labeled datasets. NASA’s archive holds large multidimensional time series data that could be used to create these foundation models. The paper was intriguing because the FM approach would address two of three challenges that were reported in a 2020 workshop focused on advancing machine learning tools to NASA’s Earth Observation data. The first challenge is the existing bottleneck caused by the lack of availability and access to large training data. The second challenge is that existing ML models do not generalize well over space and time.
The question facing us is whether we should invest time and resources to build large foundation models for the data in our archives. Will it help our data users move away from the existing paradigm of building one machine learning model per application? Can we build FMs for specific disciplines within Earth science or should the FM be built for a subset of our archives, i.e., focused on our “Cadillac” datasets that already have a large number of the different downstream applications? Another fundamental question that needs to be investigated is whether these models capture underlying physical processes.
If foundation models do fulfill the promised potential, they can play a pivotal role in accelerating science and helping uncover new insights from our archives. We can envision a future state where in our building blocks, along with the data, we utilize different FMs to support both the data and research lifecycle.
“.. most significant innovations end up generating second and third-order effects that is difficult to predict in advance” — Steven Johnson
This insight may hold true for FM models. Given the speed of innovations in technology, we should find out soon.
Rahul Ramachandran is a Sr. Research Scientist at NASA/MSFC and the IMPACT Project Manager. He periodically writes short blogs to capture ideas and thoughts to participate in the #OpenSourceScience movement by promoting #OpenIdeas. Please note that this post is not peer-reviewed and, as such, should not be considered authoritative.
